[파이썬 머신러닝 완벽 가이드 (권철민)]

2장. 사이킷런으로 시작하는 머신러닝
01. 사이킷런 소개와 특징
- 사이킷런(scikit-learn)은 가장 많이 사용 되는 머신러닝 라이브러리 중 하나.
- 파이썬 기반의 머신러닝을 위한 가장 쉽고 효율적 개발 라이브러리 제공
특징
- 가장 파이썬스러운 API 제공
- 머신러닝 위한 매우 다양한 알고리즘 개발 위한 편리한 프레임워크, API 제공
- 오랜 기간 실전 검증, 많은 환경에서 사용되는 성숙한 라이브러리
임포트 : import sklearn
02. 붓꽃 품종 예측하기
분류(Classification)은 대표적인 지도학습(Supervised Learning) 방법의 하나입니다.
학습을 위한 다양한 특징과 레이블(label, 분류 결정값) 데이터로 모델을 학습한 뒤, 별도의 데스트 데이터 세트에서 미지의 레이블을 예측합니다. 즉 명확한 정답이 주어딘 데이터를 먼저 학습을 한뒤 미지의 정답을 예측하는 방식입니다.
학습데이터 세트 : 학습을 위해 주어진 데이터 세트
테스트 데이터 세트 : 머신러닝 모델의 예측 성능을 평가하기 위해 별도로 주어진 데이터세트
사이킷런 패키지 : sklearn으로 ㅣ작하는 명명 규칙이 있다.
- sklearn.datasets 내 모듈 : 사이킷런에서 자체적으로 제공하는 데이터셋을 생성하는 모듈의 모임
- sklearn.tree 내 모듈 : 트리 기반 ML 알고리즘을 구현한 클래스의 모임
- sklearn.model_selection : 학습 데이터와 검증 데이터, 예측 데이터로 데이터를 분리, 또는 최적의 파리미터로 평가하기 위한 다양한 모듈의 모임
★ 하이퍼파라미터 : 머시러닝 알고리즘별로 최적 학습을 위해 직접 입력하는 파라미터로, 머신러닝 알고리즘의 성능을 튜닝할 수 있음
붓꽃데이터 세트를 생성하는 데는 load_iris()를 이용하며 , ML 알고리즘 의사결정트리(Decision Tree) 알고리즘으로, 이를 구현한 DecesionTreeClassifier를 적용합니다.


학습용 데이터&테스트용 데이터 분리 : train_test_split()
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=11)
- 첫번째 파라미터(x) > 데이터세트 / iris_data
- 두번째 파라미터(y) > 데이터 레이블(Label) / iris_label
- 세번째 파라미터 test_size : 전체 데이터 세트 중 테스트 데이터 세트 비율
- 네번째 파라미터 random_state : 호출할 때마다 같은 학습/테스트 용 데이터 세트를 생성하기 위해 주어지는 난수 값
※ random 값을 만드는 seed와 같은 의미. 숫자 자체는 어떤 값도 지정해도 상관 없음

[분류 예측 프로세스 정리]
1. 데이터셋 분리 : 데이터를 학습 데이터와 테스트 테이터로 분리
2. 모델 학습 : 학습된 데이터를 기반으로 ML 알고리즘을 적용해 모델 학습
3. 예측 수행 : 학습된 ML 모델을 이용해 테스트 데이터의 분류(즉, 붓꽃 종류) 예측
4. 평가 : 에측 결과값과 테스트데이터의 실제 결과값을 비교해 ML 모델 성능을 평가
03. 사이키런의 기반 프레임워크 익히기
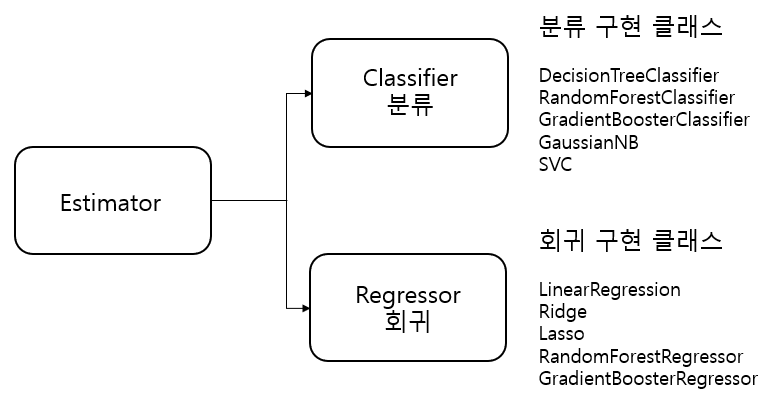
Estimator 이해 및 fit(), predict() 메서드
ML 모델 학습엔 fit(), 학습된 모델 예측엔 predict() 메서드를 사용
>지도학습의 주요 주축인 분류와 회귀의 다양한 알고리즘을 구현한 모든 사이키런 클래스는 fit()과 predict()만을 이용해 간단하게 학습과 예측 결과를 반환합니다.
Estimator 클래스 : 지도학습의 모든 알고리즘을 구현한 클래스(Classifier + Regressor)
1) 분류 알고리즘은 Classifier, 회귀 알고리즘은 Regressor로 지칭. 이 둘은 Estimator로 통칭
2) evaluation 함수, 하이퍼파라미터 튜닝 지원 클래스 등은 Estimator를 인자로 받음
비지도학습( 차원축소, 클러스터링, 피처 추출(feature Extration) 클래스 역시 fit(), transform()을 사용
1) fit() : 지도학습떄 처럼 학습을 의미하는 것이 아닌 입력 데이터의 형태에 맞춰 데이터 변환하기 위한 사전 구조를 맞추는 작업
2) transform() : 사전 구조 맞춘 뒤, 입력 데이터의 차원 변환, 클러스터링, 피처 추출 등 실제 작업을 수행
3) fit_trasform() : fit()과 transform()을 함께 사용하는것/ 다만 따로 쓰는 것과 차이점이 있다(비지도 학습을 설명하는 파트에서 상세히)
[사이킷런 주요 모듈 설명]
| 예제 데이터 | sklearn.datasets | 사이킷런에 내장된 데이터셋 |
| 데이터 전처리 | sklearn.preprocessing | 데이터 전처리에 필요한 다양한 기능 제공 |
| 피처 처리 | sklearn.feature_selection | 알고리즘에 큰 영향을 미치는 피처를 우선순위대로 선택적 적용을 수행하는 다양한 기능 제공 |
| sklearn.feature_extraction | 텍스트 데이터나 이미지 데이터의 벡터화된 피처를 추출하는 데 사용됨 | |
| 데이터 분리, 검증 & 파라미터 튜닝 | sklearn.model_selection | 교차 검증을 위한 학습용/테스트용 데이터 분리, 그리드 서치로 최적 파라미터 추출 등의 API 제공 |
| 평가 | sklearn.metrics | 분류, 회귀, 클러스터링에 대한 다양한 성능 측정 방법 제공 (Accuracy, Precision, ROC-AUC RMSE 등) |
| ML 알고리즘 | sklearn.ensemble | 앙상블 알고리즘 제공 (랜덤 포레스트, 에이다 부스트, 그래디언트 부스팅 등) |
| sklearn.linear_model | 회귀 관련 알고리즘을 지원 | |
| sklearn.naive_bayes | 나이브 베이즈 알고리즘 제공 (가우시안 NB, 다항분포 NB 등 제공) | |
| sklearn.neighbors | 최근접 이웃 알고리즘 제공 | |
| sklearn.svm | 서포트 벡터 머신 알고리즘 제공 | |
| sklearn.tree | 의사 결정 트리 알고리즘 제공 | |
| sklearn.cluster | 비지도 클러스터링 알고리즘 제공 | |
| 유틸리티 | sklearn.pipeline | 파이프라인 동안 변환과 ML 알고리즘을 하나, 연속 등을 효과적으로 구성하여 실행할 수 있는 유틸리티 제공 |
04. Model Slection 모듈 소개
학습/데이터셋 분리 - train_test_split()
- 전체 데이터를 학습/테스트 데이터셋으로 분리해줌
- from sklearn.model_selection import train_test_split()
튜플 형태로 반환 : (학습 데이터의 피처 데이터셋, 테스트 데이터의 피처 데이터셋, 학습 데이터의 레이블 데이터셋, 테스트 데이터의 레입르 데이터셋)
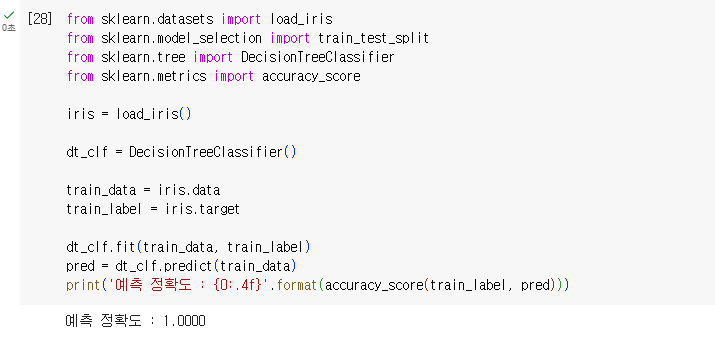
정확도가 100%가 나왔다. 이는 이미 학습한 학습데이터 세트를 기반으로 예측했기 떄문이다
예측을 수행하는 데이터 세트는 학습을 수행한 학습용 데이터 셋트가 아닌 전용 테스트 데이터 세트여야 한다.
사이킷런의 train_test_split()을 통해 데이터를 쉽게 분리 할 수 있다.
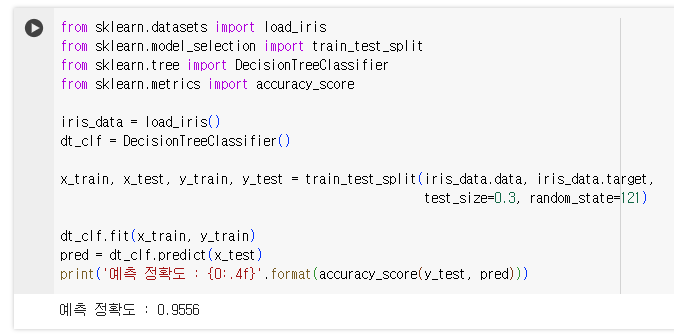
머신러닝이 어떻게 돌아가는지 확인했으니 주의할 점
- 실제 실무/프로젝트 진행시 데이터를 받으면 어떤 특징이 있는지 확인을 하는 작업(EDA)을 해야한다.
- 중복값이 있는지, 누락된 값이 있는지, 데이터에 문제가 있는지 등 체크할 필요가 있다.
데이터 탐색
- iris_df의 기본 정보를 확인하자
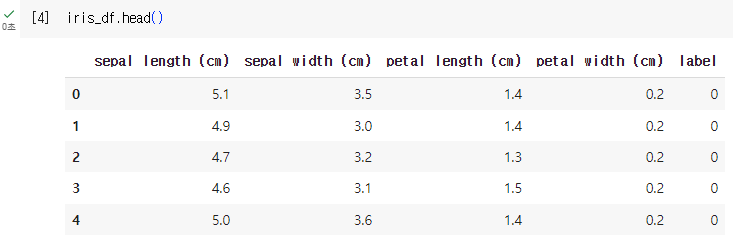
- iris_df.info() / 기본정보
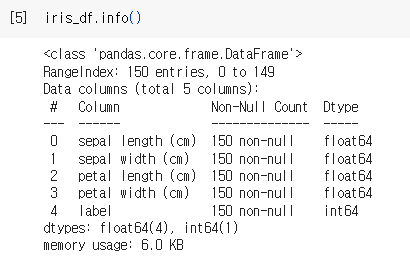
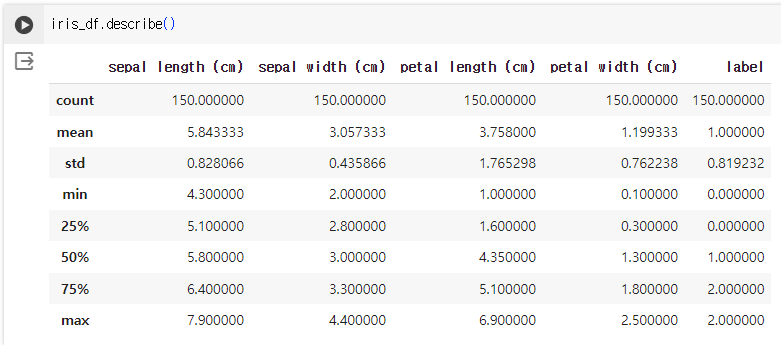
- iris_df.describe() / 평균값, 표준편차, 최소값, 최대값 등 통계정보 요약보기
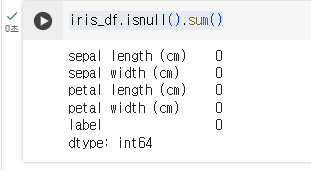
- iris_df.isnull().sum() / 결측값 확인
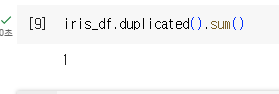
- iris_df.dupulicated().sum() / 중복데이터 확인
- iris_df[iris_df.duplicated(keep=False)] / 중복데이터 확인

- iris_df = iris_df.drop_duplicates() / 중복 데이터 삭제

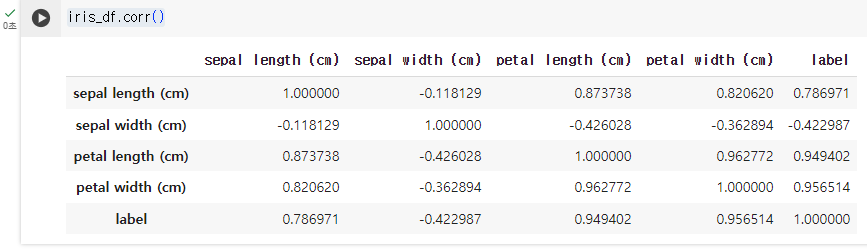
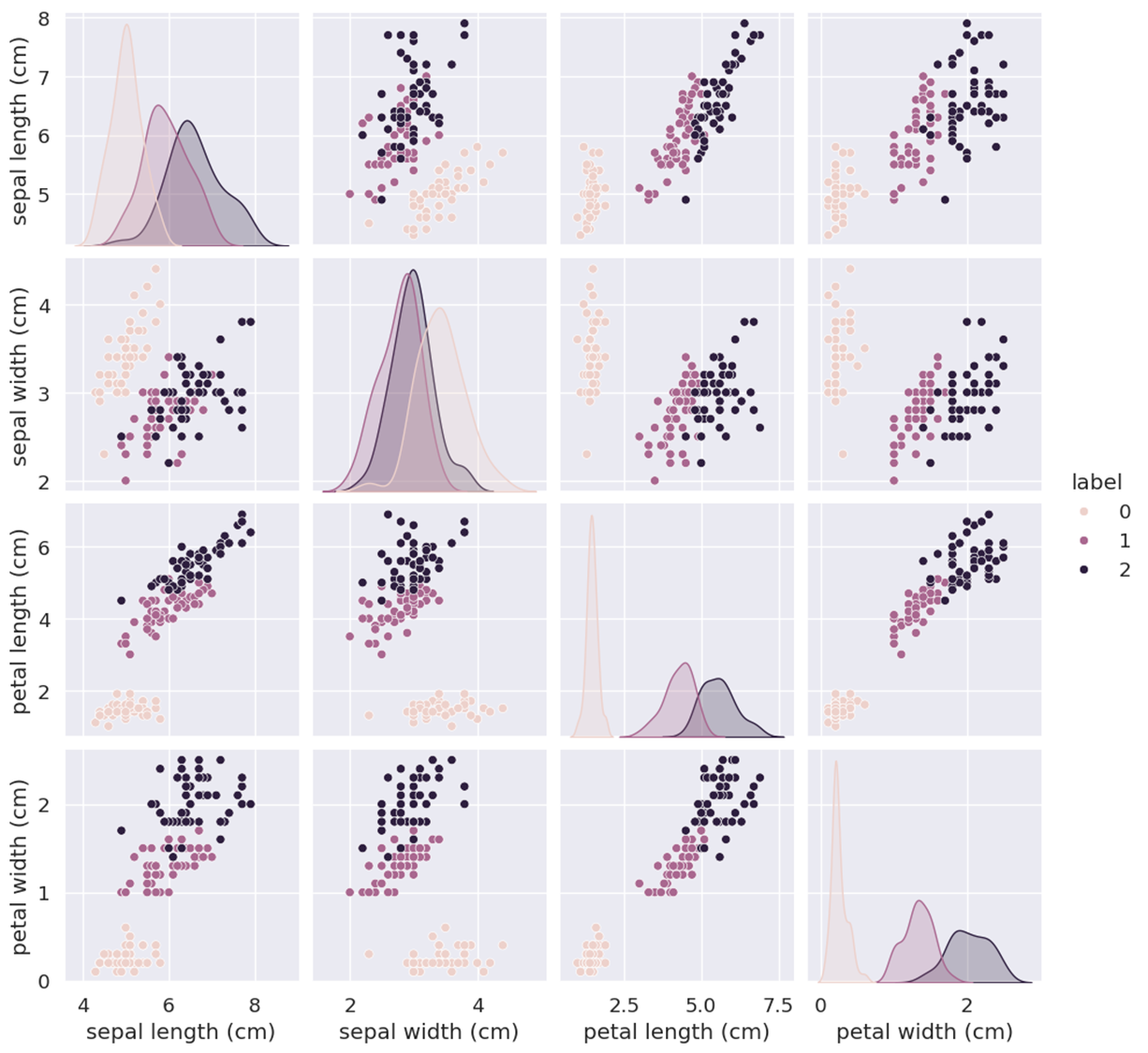
- iris_df.corr() / 변수 간의 상관 관계 분석
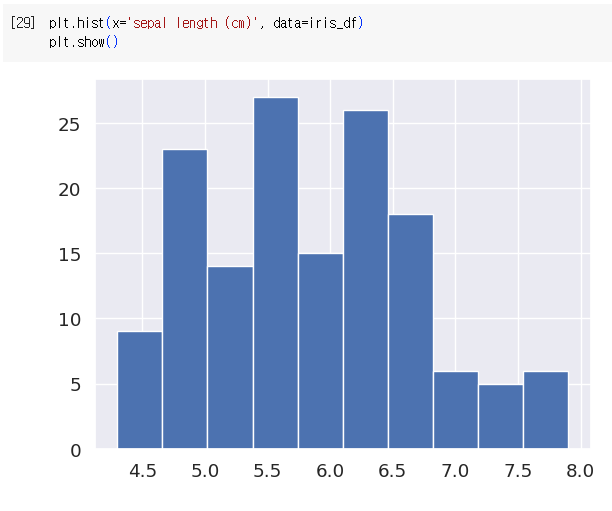
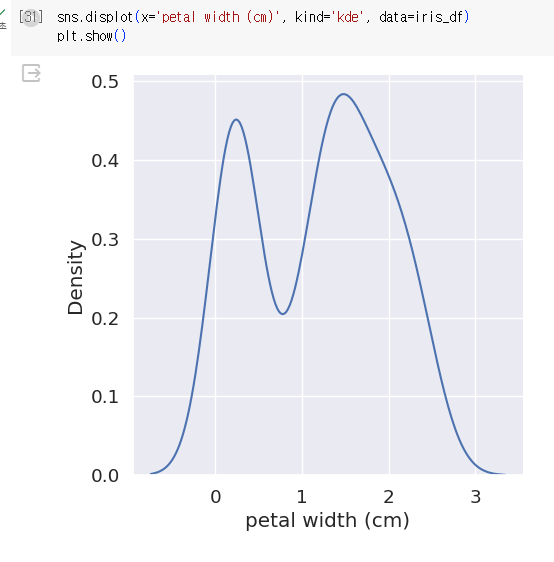
- 데이터 시각화
히트맵그래프




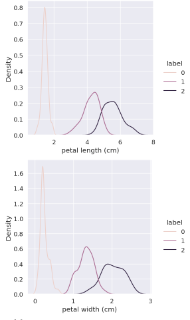

교차 검증
★ 과적합(Overfitting) :
- 모델이 학습 데이터에만 과도하게 최적화 되어, 실제 예측을 다른 데이터로 수행할 때 예측 성능이 과도하게 떨어지는 것
- 고정된 학습데이터 & 테스트 데이터로 평가할 시 테스트 데이터에만 최적의 성능을 발휘하도록 편항되게 모델을 유도하는 경향이 생김
> 결국은 테스트 데이터에만 과적합되는 학습 모델이 만들어지며, 다른 테스트용 데이터가 들어올 경우 성능이 저하가 됨
- 이를 방지하기 위해 교차검증을 이용해 다양한 학습&평가 시행
- Test test를 평가하기 전에, Training set와 Test set에서 알고리즘을 학습하고 평가하는 것이다. 즉 train과 test를 8:2 혹은 7:3으로 분할해서 70~80% 데이터만 학습하는 것이 아닌, 모든 데이터를 최소한 한 번씩 다 학습하자는 것이다. (학습데이터 증강)
교차 검증
- 간략하게 설명하자면 본과를 치르기 전 모의고사를 여러번 보는 것이다.
- 테스트 데이터셋에 대해 평가하기 전, 많은 학습과 검증 세트에서 알고리즘 학습과 평가를 수행하는 것
- 각 세트에서 수행한 평가 결과에 따라 하이퍼 파라미터 튜닝 등의 모델 최적화를 쉽게 가능
- 대부분의 ML 모델의 성능 평가는 교차 검증을 기반으로 1차 평가를 한 뒤 최종적으로 테스트 데이터셋에 적용해 평가
- ML에 사용되는 데이터 세트는 학습 + 검증 + 테스트 데이터 세트로 나눔
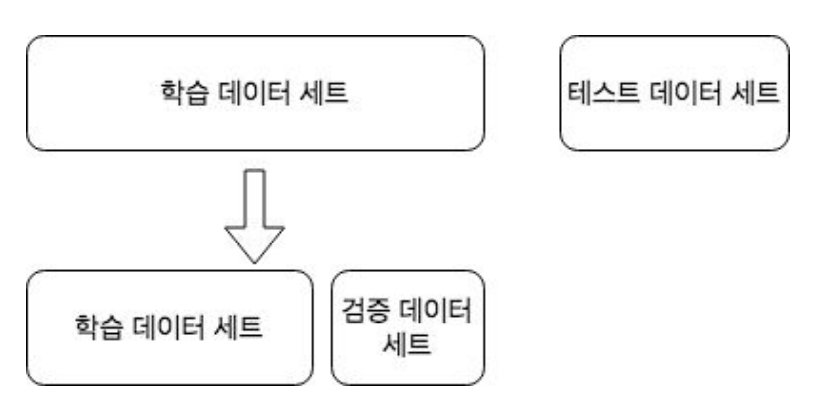
K 폴드 교차 검증
- 가장 보편적으로 사용되는 교차 검증 기법
- K개의 데이터 폴드 세트를 만들어 K번 만큼 각 폴드 세트에 학습&검증 평가를 반복적으로 수행하는 방법
- training set과 Validation을 여러번 나눈 뒤 모델의 학습을 검증한다.아래 그림에서는 데이터를 K등분(5등분)한 뒤, 1/5를 검증데이터로 나머지 4/5를 학습데이터로 나누다. 각각의 1/5를 검증데이터로 바꾸며 성능을 평가한다. 그 결과 총 5개의 성능 결과가 나올 것이고 5개의 평균을 학습 모델의 성능이라 판단한다.
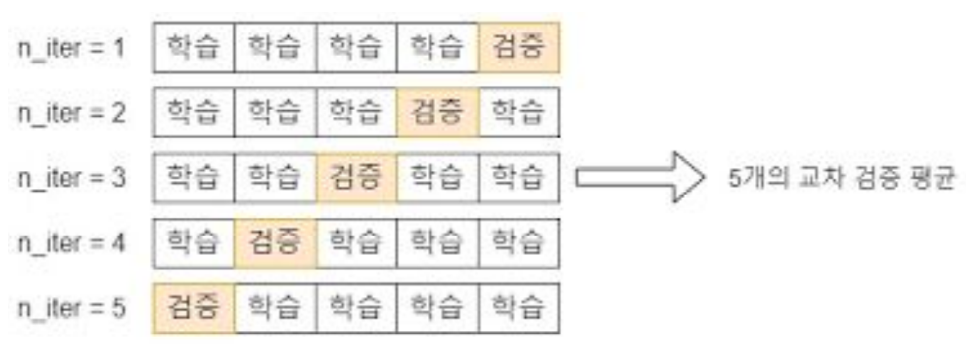
사이킷런에서는 K폴드 교차 검증 프로세스 구현을 위해 KFold와 StratifiedKFold 클래스 제공
- KFold(n_splits=n)으로 KFold 객체 생성
- KFold 객체의 split() 호출 시 전체 데이터를 n개의 폴드 데이터셋으로 분리
- split() 호출 시 학습용/검증용 데이터로 분할할 수 있는 인덱스로 반환함
- 학습용/검증용 데이터 추출은 반환된 인덱스를 기반으로 개발 코드에서 직접 수행해야 함


Stratified K 폴드
- Stratified K 폴드는 K 폴드가 레이블 데이터 집합이 원본 데이터 집합의 레이블 분포를 학습 및 테스트 스트에 제대로 분배하지 못하는 경우의 문제를 해결해준다. 이를 위해 Stratified K 폴드는 원본 데이터의 레이브 분포를 먼저 고려한 뒤 이 분포와 동일하게 학습과 검증 데이터 세트를 분배한다.
KFold는 단순히 분할할 뿐. StratifiedKFold은 라벨 값을 고려해서 분등해주겠다.



- 데이터가 Label 기준으로 골고루 분배 되었음을 확인
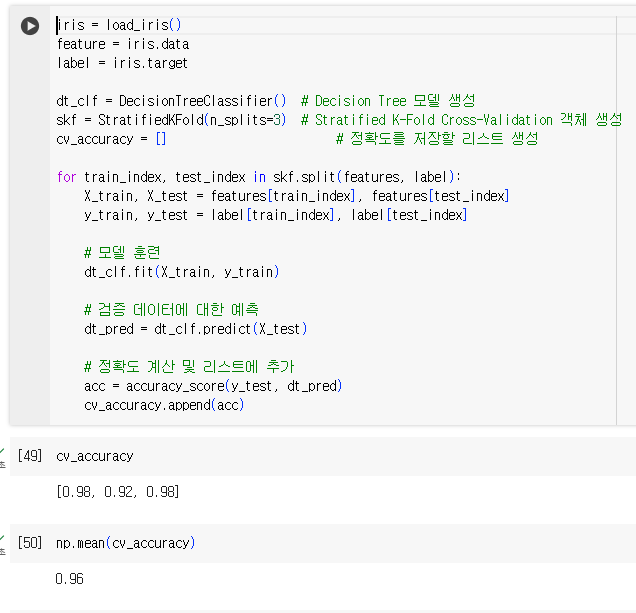
교차 검증을 보다 간편하게 사이킷런 cross_val_score()
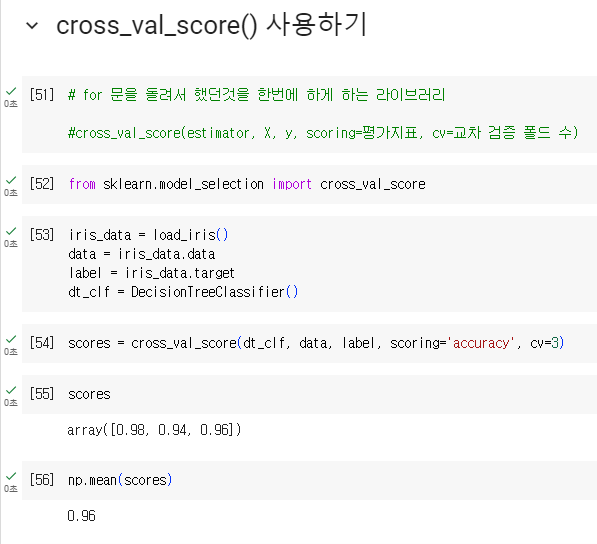
- 사이킷런은 교차 검증을 편리하게 수행할 API로 cross_val_score() 제공
KFold는 ①폴드 세트를 설정하고 , ②for 루트에서 반복으로 학습 및 테스트 데이터 인덱스 추출 한 뒤 ③반복적으로 학습과 예측을 수행하고, 예측 성능을 반환했습니다.
cross_val_score()는 이런 과정을 한꺼번에 수행하는 API입니다.
cross_val_score(estimator, X,
y=None,
scoring=None,
cv=None,
n_jobs=1,
verbose=0,
fit_params=None,
pre_dispatch='2*n_jogs')
- estimator : 사이킷런의 분류 Classifier 또는 회귀 Regressor를 의미
- X : 피처 데이터 세트
- y : 레이블 데이터 세트
- scoring : 예측 성능 평가 지표 기술
- cv : 교차 검증 폴드 수
- scoring 파라미터로 지정된 성능 지표 측정값을 배열 형태로 반환
- classifier가 입력되어 분류클래스이면 Stratified K 폴드 방식으로, 회귀이면 K 폴드 방식으로 분할
* corss_validate() : 비슷한 API로, 여러 개의 평가 지표를 반환할 수 있음. 학습 데이터에 대한 성능 평가 지표와 수행 시간도 같이 제공된다. 그러나 보통 cross_val_score() 하나로도 대부분의 경우 쉽게 사용한다.
GridSearchCV - 교차 검증과 최적 하이퍼 파라미터 튜닝을 한 번에
Classifier/Regressor 같은 알고리즘에 사용되는 하이퍼 파라미터를 교차 검증을 기반으로 순차적으로 입력하며 편리하게 최적의 파라미터를 도출할 수 있는 방안을 제공합니다.
Grid는 격자라는 뜻으로 촘촘하게 파라미터를 입력하면서 테스트를 하는 방식이다.
- 데이터 셋을 cross-validation을 위한 학습/테스트 세트로 자동 분할한 뒤에 하이퍼 파라미터 그리드에 기술된 모든 파라미터를 순차적으로 적용해 최적의 파라미터 찾음
- 단점 : 수행시간이 상대적으로 오래 걸림
GridSearchCV의 클래스 생성자 파라미터
- estimator : classifier, regressor, pipeline
- param_grid : 키 & 리스트 값 갖는 딕셔너리. estimator의 튜닝을 위해 파라미터명 & 사용될 파라미터 값들 지정
- scoring : 예측 성능을 측정할 평가 방법. 보통은 성능 평가 지표 지정할 문자열을 입력.(ex, 'accuracy') 혹은 별도 성능평가 지표 설정 가능
- cv : 교차 검증을 위해 분할되는 학습/테스트 세트 개수
- refit : 디폴트가 True. 가장 최적의 파라미터를 찾은 뒤 입력 estimator 객체를 해당 파라미터로 재학습 시킴
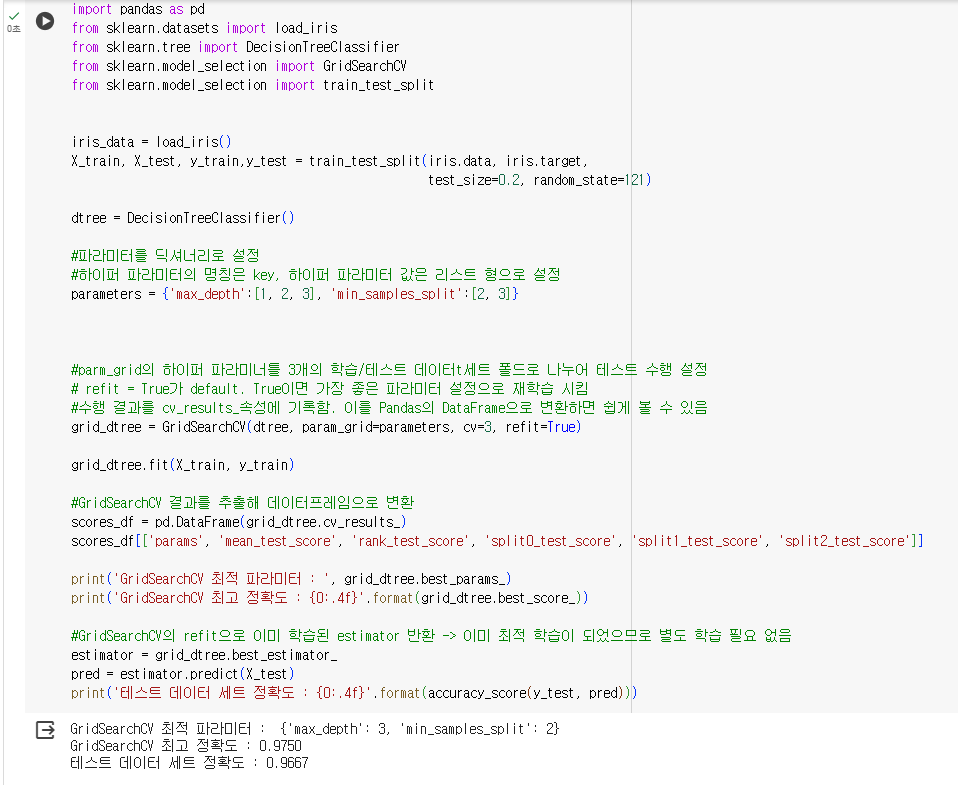
GridSearchCV.fit()을 시키면 GridSearchCV.cv_result_에 반환값을 저장 -> pandas로 보기 쉽게 확인 가능
- params : 수행할 때마다 적용된 개별 파라미터값
- rank_test_score : 하이퍼 파라미터별로 성능이 좋은 score 순위. 1에 가까울 수록 높은 순위 & 최적 파라미터
- mean_test_score : 개별 하이퍼 파라미터별로 CV의 폴딩 테스트 세트에 대해 총 수행한 평가 평균값
- best_params_, best_score_속성에 최고 성능을 내는 하이퍼 파라미터 값과 평가 결과값이 각각 저장
- best_estimator_ 속성에 refit으로 이미 학습된 estimator을 반환

'데이터 공부 > 머신러닝 공부' 카테고리의 다른 글
| 파이썬 머신러닝 완벽 가이드 (권철민) - 분류 - ① 결정트리 (0) | 2024.05.02 |
|---|---|
| 파이썬 머신러닝 완벽 가이드(권철민) - Chapter 03 평가 -② (0) | 2024.04.19 |
| 통계적 머신러닝 - Sklearn /데이터 인코딩 (0) | 2024.04.18 |
| 01. 머신러닝(marchine learning)이란? (1) | 2024.04.15 |



